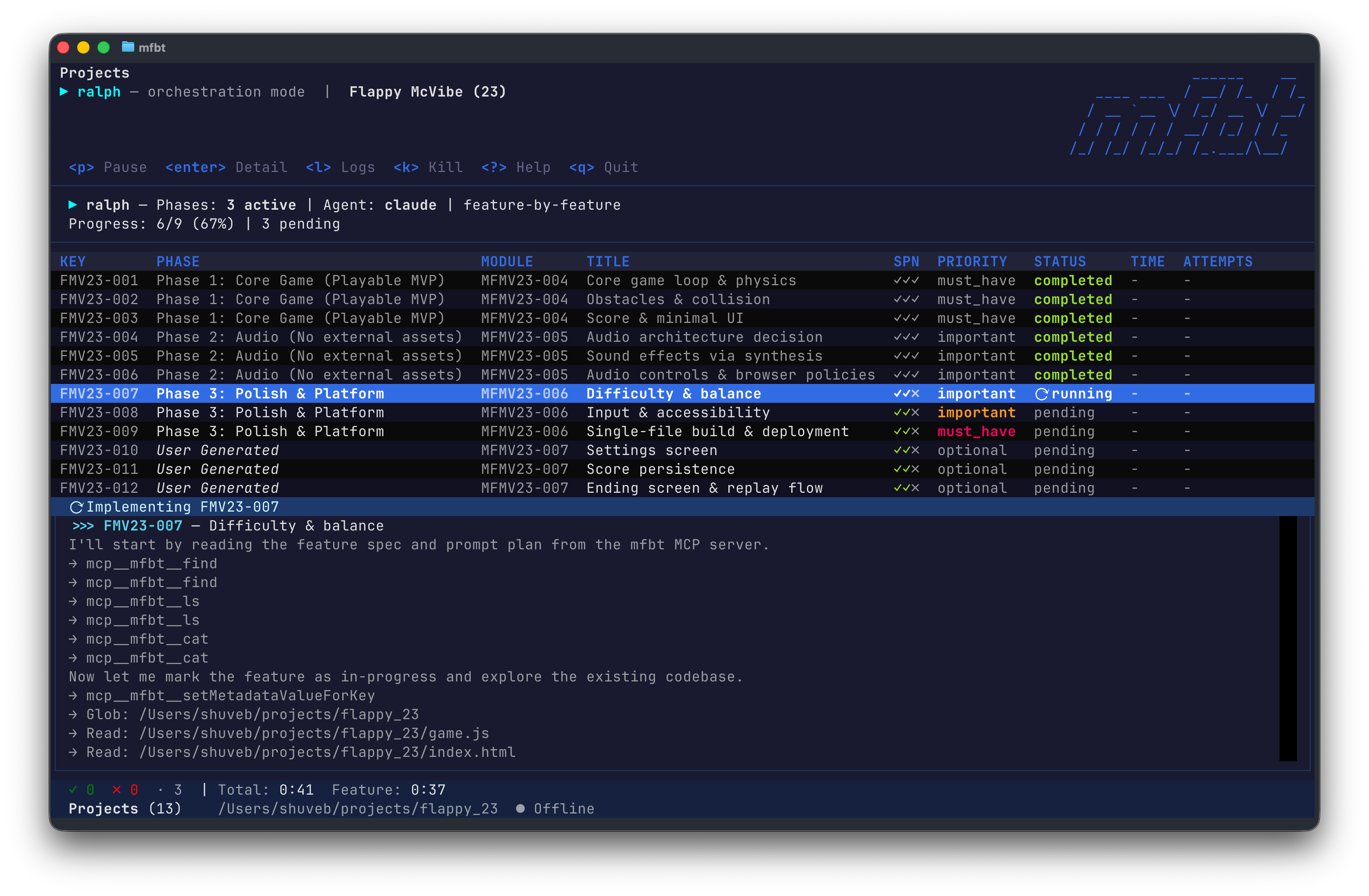
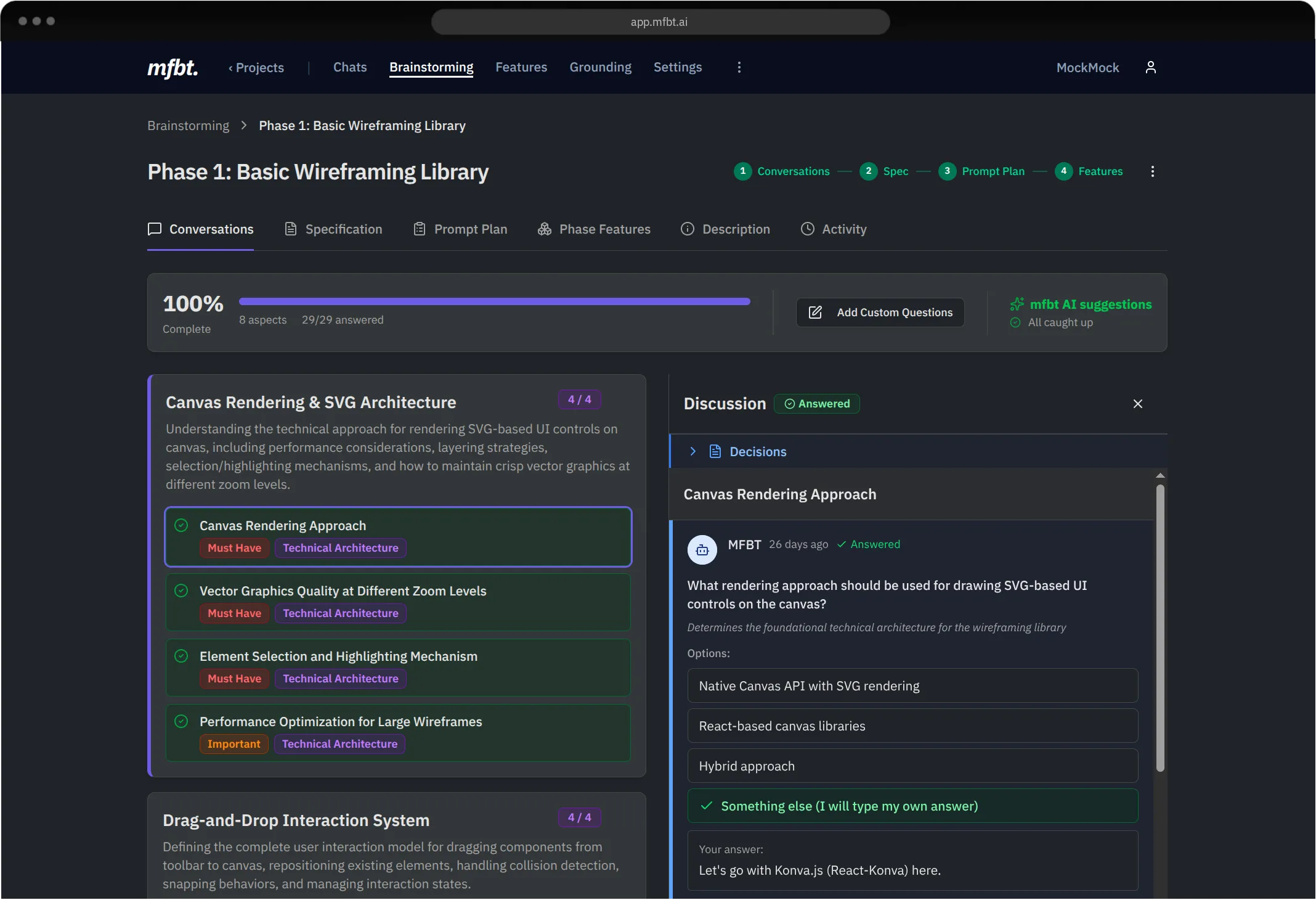
Geoffrey Huntley first described the Ralph Wiggum Loop in a January 2026 blog post. The general idea is that you can describe the outcome in detail, broken down into steps, to a coding agent. You then set up a loop that will call it until the desired outcome is achieved for every feature in the product that you want developed. The idea with a Ralph Wiggum Loop is that your end result is a product that has been developed to your specifications—without you babysitting the coding agent. To achieve a successful outcome that actually meets your needs, there are four pillars that you need to have in place.
Pillar #1: The Spec is Clear and Detailed
The first pillar is that your spec needs to be clear, unambiguous and as detailed as possible. While this means that you need to describe the outcome you want in as much detail as you can, you also need to make sure that the spec is broken down into right-sized chunks. The more specific you are, the better the coding agent will be able to understand what you want and deliver it.
Remember that LLMs are very eager. If there is a gap in the spec, they will fill it in with their own assumptions, which may not be what you want. Their eagerness is something that you should take advantage of, but you need to make sure that you are guiding it in the right direction with a clear and detailed spec. But, leave out details and you’ll end up with something. It’s just that the something here may not be what you wanted.
Pillar #2: Completion Communication
There needs to be a mechanism for the loop to communicate when a task is completed and completed successfully. The system in charge of running the loop calls the agent either with a task or lets the agent choose a task that it feels needs to be picked up next. It then needs a mechanism via which it needs to know if the task that the agent picked up was completed successfully or not. This is important because if the task was not completed successfully, the loop needs to know that and it needs to be able to take corrective action, which may involve asking the agent to try again or it may involve asking the agent to pick up a different task.
Pillar #3: Context Resets and Persistent Memory
This is an important pillar and the main reason why the coding agent needs to be controlled externally. Let’s look at both points of this pillar separately:
Context Resets: When developing a product, there’s obviously going to be a long list of tasks that need to be completed. What we don’t want is for the coding agent to develop all the features of the product utilizing the same context window. Coding agents are usually designed to compact the context window as it nears its limit by summarizing previous interactions. While developing a product with a long list of features, this means several summarizations, which means that the context window is going to be filled with summaries of summaries, which is not ideal. Loss of detail is guaranteed here. Also, remember that summaries take up precious tokens in the context window, which means that the coding agent is going to have less and less tokens available to work with as it develops more and more features of the product. Not ideal at all.
This is why it’s important to have a mechanism for resetting the context after a certain number of interactions. This way, the coding agent can start fresh with a new context window and it can focus on the task at hand without being distracted by details of previous implementations.
Persistent Memory: The second point of this pillar is that there needs to be a mechanism for the coding agent to have persistent memory. This is important because the coding agent needs to be able to remember details about features it built so far, how it built them and how to continue to build on top of them.
Also, this is warm start information for the coding agent. Having this information updated in each iteration of the loop means that the coding agent can start with a warm start in each iteration, which means that it can hit the ground running and it can be more efficient in completing the task at hand.
Pillar #4: The Agent’s Feedback Loop
When running without human supervision, the least the agent can do is to have a feedback loop with itself. This means that the agent needs to be able to evaluate its own work and determine if it has completed the task successfully or not and if not, it needs to be able to take corrective action. This ensures the quality of the output is good and it also ensures that the loop is moving forward towards the desired outcome. While there can be many mechanisms for the agent to have a feedback loop with itself, for full stack applications, the following is a good mechanism to have in place:
- Browser Javascript console logs
- Browser network logs
- Browser DOM access
- Browser screenshots
- Build logs
- Test results
- Backend logs
- Some mechanism to access the DB (readonly)
As for browser-related feedback, something like Playwright MCP or Chrome DevTools MCP is perfect.
Ralph it!
mfbt is an open source platform that helps you Brainstorm, Collaborate and Build with AI. With mfbt, you can set up a Ralph Wiggum Loop that is efficient and actually gets you what you need. In the next article, we’ll look at how to set up a Ralph Wiggum Loop on a Raspberry Pi using the mfbt CLI tool, which has built-in support for running a Ralph Wiggum Loop. We’ll also see how to use the mfbt platform to ensure that all four pillars of a Ralph Wiggum Loop are in place for successful outcomes.